
Por Erica Lux Hay algo profundamente seductor en ver a una banda que no necesita demostrar nada. No buscan likes, no persiguen tendencias, no están …
Long Play: el tiempo no pasa cuando el rock sigue vivo
Por Erica Lux Hay algo profundamente seductor en ver a una banda que no necesita demostrar nada. No buscan likes, no persiguen tendencias, no están …
Long Play: el tiempo no pasa cuando el rock sigue vivo
Se han mencionado ya los diferentes modelos de síntesis de voz. El reto que se enfrenta hoy en el desarrollo de síntesis de voz no es únicamente la forma de emular la voz humana, sino también encontrar un sistema de control eficiente para producirla.
Los tres métodos de síntesis aquí mencionados resultan complicados de manipular, los tres por la misma razón: Los múltiples parámetros que implican modificarse para producir una frase.
Los sistemas de cómputo actuales han facilitado este control multi-parámetro, gracias a la rapidez de los procesadores se han podido programar los diferentes parámetros y ejecutar en fracciones de segundo. Esto desafortunadamente sólo ha solucionado parte del problema ya que los investigadores en tecnologías del habla han descubierto que el lenguaje hablado es mucho más complicado de recrear de lo que parece, no sólo por la emulación de los fonemas sino por la articulación de las palabras.
El método tradicional para generar una frase sintetizada es teniendo la frase que se desea producir como texto a manera de entrada denominado Text-to-speech, desde luego los fonemas (sonido de las palabras) no necesariamente coincide siempre con los grafemas (letras), por esta razón es necesario un proceso previo de interpretación de texto. El proceso consiste en una serie de reglas por lo que se conoce como synthesis by rules.
A continuación, se presenta la explicación de esta etapa en la síntesis de texto tomado de las notas de Herrera (Camacho & Ávila, 2013). Se hará mención de la terminología utilizada en Festival porque fue el sintetizador que se estudió (Taylor, Black, & Caley, 1998; Tokuda, Zen, & Black, 2002) debido a ser uno de los mejores en su clase y que en él están basados los actuales sistemas de síntesis que se estudiaron.
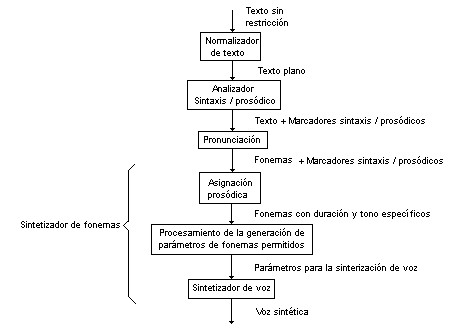
En la figura 1 se muestra un diagrama de bloques de las varias etapas en un sistema texto a voz concatenado. La entrada del sistema es un texto sin restricciones en forma de una secuencia de caracteres, incluyendo números, abreviaciones y signos de puntuación. La función del normalizador de texto es procesar cualquier carácter no alfabético: los signos de puntuación que se identifiquen se dejarán en su lugar; las abreviaciones serán expandidas a su forma completa; las cantidades se expandirán en sus formas completas también, por ejemplo “£2.75” se convertirá en “dos libras y setenta y cinco centavos”. Esta etapa se conoce en Festival como tokenización. Los programadores de Festival decidieron demoníaca como token al árbol de posibilidades correspondiente a un grafema. Normalmente hay una única posibilidad de token por grafema, sin embargo, en el caso de los números o determinados signos de puntuación, las posibilidades aumentan considerablemente.
La salida del normalizador de texto es texto plano en forma de una secuencia de caracteres alfabéticos y signos de puntuación. Aquí se fonetizan todos los grafemas encontrados, por ejemplo, “casa” se convierte en “kasa”, “queso se vuelve “keso”, “hola” se modifica a “ola”, etc. En festival se denomina como lexicon a los caracteres que denotan la sonoridad del fonema en cuestión. Por ejemplo: “photography” es en lexicon, (((f@)0)((tog)1)((r@f)0)((ii)0))).
El siguiente módulo llamado analizador de sintaxis/prosodia usa un algoritmo de análisis para segmentar el texto de tal forma que se le pueda asignar una entonación y ritmo significativos. Esto normalmente involucra un análisis gramatical, esto es, la identificación de sustantivos, verbos, preposiciones, conjunciones, etc. El módulo asigna marcadores al texto, los cuales indican, por ejemplo, las sílabas acentuadas, los puntos de acentuación tónica en un patrón de entonación y los tipos de patrones de entonación a ser usados en varias partes de la locución.
Es bien sabido en el campo de la lingüística que los fonemas modifican sus sonidos dependiendo del fonema que lo antecede y del que lo precede. Por esta razón los sistemas de texto a voz necesitan puntos de comparación para saber cuál es la mejor opción de fonema a sintetizar. De ahí la importancia de dotar al sistema de una base de datos o corpus que contenga diferentes opciones de fonemas. Dentro de la base de datos, cada fonema viene etiquetado con su probabilidad de ocurrencia.
La forma de calcular la probabilidad máxima de ocurrencia se hace mediante la resolución de árboles determinísticos. Normalmente los pasos a seguir son los siguientes:
Se denomina CART (Clasiffication and Regression Tree) al sistema probabilístico de extracción de datos que se aplica en este proceso de selección. Un ejemplo del árbol de clasificación y regreso aplicado a Festival es el siguiente:
La figura ilustra el árbol determinístico:
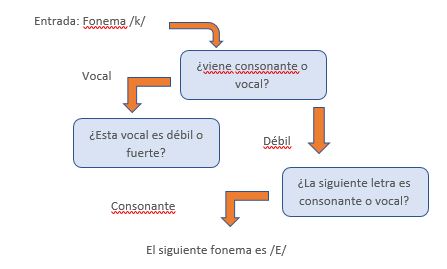
Las iteraciones necesarias se realizan hasta completar el texto presentado como entrada. Al tiempo que el programa va concatenando los diferentes difonemas que forman parte del corpus. En su esquema más básico, el programa es limitado en cuanto a modificaciones en la prosodia del texto sintetizado.
2. Selección de unidades
Anteriormente expuesto en este documento, se tiene ya mencionado que en la síntesis concatenativa se parte de fragmentos de voz previamente grabados por un profesional. A partir de estos fragmentos de voz es como se van a reconstruir diferentes palabras.
Se denomina síntesis de voz por unidades (Dutoit, 2008) a aquel tipo de síntesis, donde las frases sintetizadas son logradas a través de la concatenación de palabras completas extraídas de una base de datos -llamada también corpus- de frases pre-grabadas. A últimos años, los especialistas en síntesis de voz prefieren utilizar este sistema de selección unidades sobre otros, como el de fonemas o difonemas, ya que al trabajar con palabras o frases completas es posible mantener una mejor inteligibilidad y naturalidad en cada frase. Las distintas unidades de voz tienen un sistema de etiquetado el cual permite después ubicarlas como vectores de observación (Tokuda, Yoshimura, & Masuko, 2000; Tokuda et al., 2002) que son estados dentro del sistema de selección por modelos ocultos de Markov (HMM) -del que se hablará más adelante en el texto-. Otra manera de hacer la selección de unidades es por medio de un algoritmo estadístico de conjuntos de unidades con elementos comunes, de aquí se desprenden dos métodos propuestos por Alan Black: Clustering (Black & Taylor, 1997) y CLUSTERGEN (Black, 2006). Ambos métodos son la base de selección del conocido sistema de síntesis de voz FESTIVAL, desarrollado en conjunto por CMU y la Universidad de Edinburgo. Ejemplos de sonido de este sistema se puede escuchar en los audios:
Con el paso del tiempo, la selección de unidades utilizando HMM ha demostrado ser mucho más eficiente que los métodos basados en clusters por lo que incluso FESTIVAL la ha adoptado. Por esta razón no se hablará con detalle en el texto de los sistemas Clustering y CLUSTERGEN.
Referencias
Black, A. (2006). CLUSTERGEN: a statistical parametric synthesizer using trajectory modeling. INTERSPEECH. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/is2006/IS061394.PDF
Black, A., & Taylor, P. (1997). Automatically clustering similar units for unit selection in speech synthesis. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1236
Camacho, A. H., & Ávila, F. D. R. (2013). Development of a Mexican Spanish Synthetic Voice Using Synthesizer Modules of Festival Speech and HTSStraight. International Journal of Computer and Electrical Engineering, 36–39. https://doi.org/10.7763/IJCEE.2013.V5.657
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Taylor, P., Black, A., & Caley, R. (1998). The architecture of the Festival speech synthesis system. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1032
Tokuda, K., Yoshimura, T., & Masuko, T. (2000). Speech parameter generation algorithms for HMM-based speech synthesis. , Speech, and Signal …. Retrieved from http://ieeexplore.ieee.org/abstract/document/861820/
Tokuda, K., Zen, H., & Black, A. (2002). An HMM-based speech synthesis system applied to English. IEEE Speech Synthesis Workshop. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/IEEE2002/hmmenglish.pdf
Black, A. (2006). CLUSTERGEN: a statistical parametric synthesizer using trajectory modeling. INTERSPEECH. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/is2006/IS061394.PDF
Black, A., & Taylor, P. (1997). Automatically clustering similar units for unit selection in speech synthesis. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1236
Camacho, A. H., & Ávila, F. D. R. (2013). Development of a Mexican Spanish Synthetic Voice Using Synthesizer Modules of Festival Speech and HTSStraight. International Journal of Computer and Electrical Engineering, 36–39. https://doi.org/10.7763/IJCEE.2013.V5.657
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Taylor, P., Black, A., & Caley, R. (1998). The architecture of the Festival speech synthesis system. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1032
Tokuda, K., Yoshimura, T., & Masuko, T. (2000). Speech parameter generation algorithms for HMM-based speech synthesis. , Speech, and Signal …. Retrieved from http://ieeexplore.ieee.org/abstract/document/861820/
Tokuda, K., Zen, H., & Black, A. (2002). An HMM-based speech synthesis system applied to English. IEEE Speech Synthesis Workshop. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/IEEE2002/hmmenglish.pdf
