El primer libro de autoría de Carlos Franco, el cual resume de manera amplia su trabajo de tesis doctoral.

Se puede descargar una versión pdf aquí:
Franco_Herrera_Escalante_Sistema de Sintesis de Voz en español de Mexico
El primer libro de autoría de Carlos Franco, el cual resume de manera amplia su trabajo de tesis doctoral.
Se puede descargar una versión pdf aquí:
Franco_Herrera_Escalante_Sistema de Sintesis de Voz en español de Mexico
Se han mencionado ya los diferentes modelos de síntesis de voz. El reto que se enfrenta hoy en el desarrollo de síntesis de voz no es únicamente la forma de emular la voz humana, sino también encontrar un sistema de control eficiente para producirla.
Los tres métodos de síntesis aquí mencionados resultan complicados de manipular, los tres por la misma razón: Los múltiples parámetros que implican modificarse para producir una frase.
Los sistemas de cómputo actuales han facilitado este control multi-parámetro, gracias a la rapidez de los procesadores se han podido programar los diferentes parámetros y ejecutar en fracciones de segundo. Esto desafortunadamente sólo ha solucionado parte del problema ya que los investigadores en tecnologías del habla han descubierto que el lenguaje hablado es mucho más complicado de recrear de lo que parece, no sólo por la emulación de los fonemas sino por la articulación de las palabras.
El método tradicional para generar una frase sintetizada es teniendo la frase que se desea producir como texto a manera de entrada denominado Text-to-speech, desde luego los fonemas (sonido de las palabras) no necesariamente coincide siempre con los grafemas (letras), por esta razón es necesario un proceso previo de interpretación de texto. El proceso consiste en una serie de reglas por lo que se conoce como synthesis by rules.
A continuación, se presenta la explicación de esta etapa en la síntesis de texto tomado de las notas de Herrera (Camacho & Ávila, 2013). Se hará mención de la terminología utilizada en Festival porque fue el sintetizador que se estudió (Taylor, Black, & Caley, 1998; Tokuda, Zen, & Black, 2002) debido a ser uno de los mejores en su clase y que en él están basados los actuales sistemas de síntesis que se estudiaron.
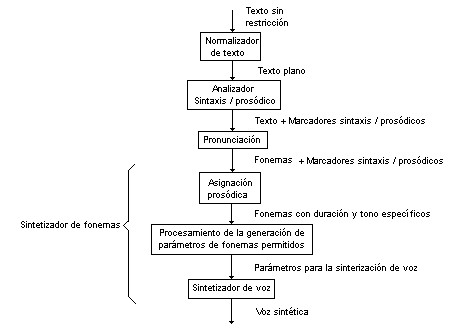
En la figura 1 se muestra un diagrama de bloques de las varias etapas en un sistema texto a voz concatenado. La entrada del sistema es un texto sin restricciones en forma de una secuencia de caracteres, incluyendo números, abreviaciones y signos de puntuación. La función del normalizador de texto es procesar cualquier carácter no alfabético: los signos de puntuación que se identifiquen se dejarán en su lugar; las abreviaciones serán expandidas a su forma completa; las cantidades se expandirán en sus formas completas también, por ejemplo “£2.75” se convertirá en “dos libras y setenta y cinco centavos”. Esta etapa se conoce en Festival como tokenización. Los programadores de Festival decidieron demoníaca como token al árbol de posibilidades correspondiente a un grafema. Normalmente hay una única posibilidad de token por grafema, sin embargo, en el caso de los números o determinados signos de puntuación, las posibilidades aumentan considerablemente.
La salida del normalizador de texto es texto plano en forma de una secuencia de caracteres alfabéticos y signos de puntuación. Aquí se fonetizan todos los grafemas encontrados, por ejemplo, “casa” se convierte en “kasa”, “queso se vuelve “keso”, “hola” se modifica a “ola”, etc. En festival se denomina como lexicon a los caracteres que denotan la sonoridad del fonema en cuestión. Por ejemplo: “photography” es en lexicon, (((f@)0)((tog)1)((r@f)0)((ii)0))).
El siguiente módulo llamado analizador de sintaxis/prosodia usa un algoritmo de análisis para segmentar el texto de tal forma que se le pueda asignar una entonación y ritmo significativos. Esto normalmente involucra un análisis gramatical, esto es, la identificación de sustantivos, verbos, preposiciones, conjunciones, etc. El módulo asigna marcadores al texto, los cuales indican, por ejemplo, las sílabas acentuadas, los puntos de acentuación tónica en un patrón de entonación y los tipos de patrones de entonación a ser usados en varias partes de la locución.
Es bien sabido en el campo de la lingüística que los fonemas modifican sus sonidos dependiendo del fonema que lo antecede y del que lo precede. Por esta razón los sistemas de texto a voz necesitan puntos de comparación para saber cuál es la mejor opción de fonema a sintetizar. De ahí la importancia de dotar al sistema de una base de datos o corpus que contenga diferentes opciones de fonemas. Dentro de la base de datos, cada fonema viene etiquetado con su probabilidad de ocurrencia.
La forma de calcular la probabilidad máxima de ocurrencia se hace mediante la resolución de árboles determinísticos. Normalmente los pasos a seguir son los siguientes:
Se denomina CART (Clasiffication and Regression Tree) al sistema probabilístico de extracción de datos que se aplica en este proceso de selección. Un ejemplo del árbol de clasificación y regreso aplicado a Festival es el siguiente:
La figura ilustra el árbol determinístico:
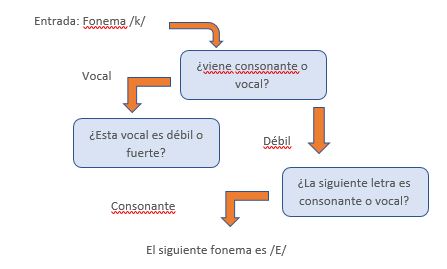
Las iteraciones necesarias se realizan hasta completar el texto presentado como entrada. Al tiempo que el programa va concatenando los diferentes difonemas que forman parte del corpus. En su esquema más básico, el programa es limitado en cuanto a modificaciones en la prosodia del texto sintetizado.
2. Selección de unidades
Anteriormente expuesto en este documento, se tiene ya mencionado que en la síntesis concatenativa se parte de fragmentos de voz previamente grabados por un profesional. A partir de estos fragmentos de voz es como se van a reconstruir diferentes palabras.
Se denomina síntesis de voz por unidades (Dutoit, 2008) a aquel tipo de síntesis, donde las frases sintetizadas son logradas a través de la concatenación de palabras completas extraídas de una base de datos -llamada también corpus- de frases pre-grabadas. A últimos años, los especialistas en síntesis de voz prefieren utilizar este sistema de selección unidades sobre otros, como el de fonemas o difonemas, ya que al trabajar con palabras o frases completas es posible mantener una mejor inteligibilidad y naturalidad en cada frase. Las distintas unidades de voz tienen un sistema de etiquetado el cual permite después ubicarlas como vectores de observación (Tokuda, Yoshimura, & Masuko, 2000; Tokuda et al., 2002) que son estados dentro del sistema de selección por modelos ocultos de Markov (HMM) -del que se hablará más adelante en el texto-. Otra manera de hacer la selección de unidades es por medio de un algoritmo estadístico de conjuntos de unidades con elementos comunes, de aquí se desprenden dos métodos propuestos por Alan Black: Clustering (Black & Taylor, 1997) y CLUSTERGEN (Black, 2006). Ambos métodos son la base de selección del conocido sistema de síntesis de voz FESTIVAL, desarrollado en conjunto por CMU y la Universidad de Edinburgo. Ejemplos de sonido de este sistema se puede escuchar en los audios:
Con el paso del tiempo, la selección de unidades utilizando HMM ha demostrado ser mucho más eficiente que los métodos basados en clusters por lo que incluso FESTIVAL la ha adoptado. Por esta razón no se hablará con detalle en el texto de los sistemas Clustering y CLUSTERGEN.
Referencias
Black, A. (2006). CLUSTERGEN: a statistical parametric synthesizer using trajectory modeling. INTERSPEECH. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/is2006/IS061394.PDF
Black, A., & Taylor, P. (1997). Automatically clustering similar units for unit selection in speech synthesis. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1236
Camacho, A. H., & Ávila, F. D. R. (2013). Development of a Mexican Spanish Synthetic Voice Using Synthesizer Modules of Festival Speech and HTSStraight. International Journal of Computer and Electrical Engineering, 36–39. https://doi.org/10.7763/IJCEE.2013.V5.657
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Taylor, P., Black, A., & Caley, R. (1998). The architecture of the Festival speech synthesis system. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1032
Tokuda, K., Yoshimura, T., & Masuko, T. (2000). Speech parameter generation algorithms for HMM-based speech synthesis. , Speech, and Signal …. Retrieved from http://ieeexplore.ieee.org/abstract/document/861820/
Tokuda, K., Zen, H., & Black, A. (2002). An HMM-based speech synthesis system applied to English. IEEE Speech Synthesis Workshop. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/IEEE2002/hmmenglish.pdf
Black, A. (2006). CLUSTERGEN: a statistical parametric synthesizer using trajectory modeling. INTERSPEECH. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/is2006/IS061394.PDF
Black, A., & Taylor, P. (1997). Automatically clustering similar units for unit selection in speech synthesis. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1236
Camacho, A. H., & Ávila, F. D. R. (2013). Development of a Mexican Spanish Synthetic Voice Using Synthesizer Modules of Festival Speech and HTSStraight. International Journal of Computer and Electrical Engineering, 36–39. https://doi.org/10.7763/IJCEE.2013.V5.657
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Taylor, P., Black, A., & Caley, R. (1998). The architecture of the Festival speech synthesis system. Retrieved from https://www.era.lib.ed.ac.uk/handle/1842/1032
Tokuda, K., Yoshimura, T., & Masuko, T. (2000). Speech parameter generation algorithms for HMM-based speech synthesis. , Speech, and Signal …. Retrieved from http://ieeexplore.ieee.org/abstract/document/861820/
Tokuda, K., Zen, H., & Black, A. (2002). An HMM-based speech synthesis system applied to English. IEEE Speech Synthesis Workshop. Retrieved from http://www.scs.cmu.edu/afs/cs.cmu.edu/Web/People/awb/papers/IEEE2002/hmmenglish.pdf
Los coeficientes obtenidos a partir de un proceso de filtrado conocido como Mel-Cepstral, son un conjunto de valores numéricos que resumen la información básica de las características que constituyen una señal de voz (Holmes & Holmes, 2001). El procedimiento para obtenerlos está basado en dos conceptos: El rango de frecuencias Mel y la separación de frecuencias por medio de Cepstrum.
El rango de frecuencias Mel está basado en la reducción de frecuencias de la señal de voz teniendo como referencia el rango auditivo humano, es decir, aquellas frecuencias que se pueden percibir más fácilmente. Por otro lado, Cepstrum es un concepto matemático que separa de la señal de voz en dos bandas de frecuencias baja y alta. La baja corresponde a los formantes de los fonemas producidos debido a las cavidades del tracto vocal y la banda alta es relativa a la excitación en las cuerdas vocales. Esta última es una señal periódica muy particular a los distintos fonemas independientemente de las variaciones en el tracto vocal.
El algoritmo de MFCC se puede resumir de acuerdo al diagrama siguiente:

Ahora bien, en cada una de las ventanas se aplica un conjunto de filtros pasabanda cuyo número varía de acuerdo a la precisión deseada. Al resultado de la señal filtrada en cada uno de los filtros es después una función logarítmica. Es a nueva señal de acuerdo al concepto de Cepstrum es necesario volver a aplicar una FFT la cual, debido a su simetría, se obtiene mediante una transformada coseno discreta.

Alogoritmo detallado
A continuación, hacemos una descripción a detalle de la obtención de los coeficientes MFCC. La figura 1 muestra el sistema en esquema.

Los MFCC son una manera compacta de almacenar sonido. No son otra cosa más que números que revelan las diferentes amplitudes de la señal, pero no tienen en sí mismos energía acústica codificada.
Si se van a utilizar para hacer síntesis, hacen la función de un filtro a través del cual pasa una fuente sonora dual que emite una señal sinusoidal para sonidos vocales y una señal de ruido blanco para sonidos sordos.
Referencias
Davis, S., & Mermelstein, P. (1978). Evaluation of acoustic parameters for monosyllabic word identification. The Journal of the Acoustical Society of. Retrieved from http://asa.scitation.org/doi/abs/10.1121/1.2004059
Holmes, J. N., & Holmes, W. (Wendy J. . (2001). Speech synthesis and recognition. Taylor & Francis.
Desde principios del siglo XX se han realizado distintos esfuerzos para generar “máquinas parlantes”, o de manera más correcta: Realizar Síntesis de Voz. Sin embargo, a casi un siglo de que apareció el primer sintetizador de voz eléctrico de Homer Dudley que se tiene documentado (“Homer Dudley’s Speech Synthesisers,” n.d.) llamado VODER (ver figura). No se ha terminado de lograr el sueño de tener un sistema de síntesis de voz que resulte indistinguible de la voz humana. Si bien las voces sintéticas de la actualidad cumplen casi cabalmente el requisito de inteligibilidad, aún no es así con el de la expresión. La combinación de estos dos es lo que dota de naturalidad a los sistemas de voz artificial.

Existen tres sistemas de síntesis vocal: síntesis de formantes, síntesis articulatoria y síntesis concatenativa. A continuación, se explica con detalle en que consiste cada uno.
Se define como frecuencias formantes a aquellas frecuencias características de un fonema. Tales sonidos permanecen constantes en cada emisión de frase, independientemente de la entonación o intensidad con la que la frase haya sido producida. Gracias a ésta característica sabemos que los fonemas pueden ser identificados en todo momento por estas frecuencias.
Fisiológicamente hablando, las formantes son resultado de las resonancias producidas a lo largo del tracto vocal de la onda sonora proveniente de la glotis que tuvo su origen en la vibración de las cuerdas vocales producida por una corriente de aire en los pulmones.
En la voz humana existen dos tipos de sonidos: vocales y sordos o no-vocales, los primeros son resultado de la vibración de las cuerdas vocales y los segundos resultan del flujo de aire que pasa directamente de los pulmones al tracto vocal.
Este proceso de generación artificial de formantes se puede lograr en un sistema de procesamiento de señales electrónicas. La señal proveniente de las cuerdas vocales se simula con una fuente sinusoidal. Los sonidos no-vocales, por su parte, se emulan a través de una fuente de ruido blanco. Las frecuencias formantes se logran pasando dicha fuente a través de un conjunto de filtros pasa banda. Un modelo que ha sido referente en este tipo de sistemas de fuente-filtros es el sintetizador de Klatt (Klatt, 1982) el cual fue de los primeros sistemas de síntesis en software cuyo algoritmo y código fuente se publicaron a detalle.
La síntesis articulatoria está basada principalmente en el trabajo de Fant (Fant, 1970) que comenzó desde principios de los 60. Este tipo de síntesis pretende modelar las características físicas haciendo un estudio de la geometría del tracto vocal, principalmente de su largo y su área transversal. Posteriormente mediante ecuaciones de movimiento de fluidos se hace un modelo matemático de los fenómenos acústicos que tienen lugar adentro del tracto.
El concepto físico de la presión que el aire ejerce sobre el tracto vocal, así como el chorro de aire que viaja dentro de él se simplifica observando el tracto vocal como una serie de tubos interconectados. Así como el tejido del tracto vocal cambia su grosor de acuerdo con el sonido que se emite, cada uno de estos tubos tiene un diámetro distinto correspondiente a un fonema determinado.
Este modelo tubular es referente en dos tipos de síntesis: la de circuitos acústicos y la de Linear Predictive Coding o LPC. Se hablará de LPC y cómo utiliza el modelo tubular más adelante en este documento, en lo referente a circuitos acústicos podemos mencionar que el modelo tracto vocal-tubular fue muy popular a mediados del siglo veinte ya que constituyó el principio para la elaboración de una familia de sintetizadores de voz eléctricos.
Muchos de ellos fueron llevados a la práctica utilizando analogías acústicas-eléctricas. Destaca el trabajo de Stevens, Kasowski con Fant (Stevens, Kasowski, & Fant, 1953). La síntesis articulatoria perdió un poco de popularidad durante los 60 y 70, no fue sino hasta 1982 con el trabajo de Maeda que se reutilizó la analogía electro-acústica y sin duda al día de hoy el trabajo más relevante donde se emplea síntesis articulatoria es Vocal Tract Lab (Birkholz & Jackel, 2003; Birkholz, Jackèl, & Kroger, 2006), el cual continúa vigente en su interesante proyecto en el sitio vocaltractlab.
Sin importar cómo fueron generados los fonemas, ya fuera grabadas por una persona o mediante una parametrización de la que se hablará más adelante. Para hacer síntesis es necesario es necesario enlazar los fonemas uno con otro luego de ser producidos. A este tipo de síntesis de voz se le conoce como síntesis concatenativa.
La síntesis concatenativa es la más eficiente en sistemas de síntesis al día de hoy. En la síntesis concatenativa se pueden modificar más detalladamente las unidades mínimas de lenguaje logrando una mayor naturalidad cuando éstos se producen.
Como consecuencia de lo anterior, la inteligibilidad y entonación de una voz artificial de síntesis concatenativa superan a aquellas logradas con síntesis articulatoria o con síntesis de formantes.
Los métodos para emular la prosodia (tono y duración) en la concatenación de las palabras son principalmente los basados en el principio de Suma-Traslape (Overlap-Add), en estos métodos destacan PSOLA, MBROLA y selección de unidades.
Se dice que (Dutoit, 2008) para producir lenguaje hablado de manera inteligible, se requiere de la habilidad de generar lenguaje continuo coarticulado. Lo cual nos conduce a pensar que los puntos de transición entre fonemas son mucho más importantes para la inteligibilidad de lo que son los segmentos estables. Incluso los fonemas vocales largos y sostenidos varían en amplitud y frecuencia, además de que contienen elementos inarmónicos.
Con base en éste argumento, la síntesis de voz concatenativa busca inteligibilidad “pegando” trozos de habla en lugar de fonemas aislados. Esto conlleva a una mejor coarticulación.
Un primer intento de lograr una concatenación más precisa es mediante el uso de difonemas como unidades mínimas para producir lenguaje hablado.
Normalmente, el difonema comienza y termina con una parte estable como se muestra en la figura

El problema es que la cantidad de difonemas presentes en un idioma es enorme. Típicamente una base de datos de difonemas es de al menos 1500 unidades. En términos prácticos, tres minutos de habla muestreados a 16 KHz con resolución de 16 bit suman alrededor de 5 MB.
Para resolver este problema, se busca una lista de palabras donde aparezca al menos dos veces cada difonema. El texto se lee por un locutor profesional para evitar mucha variación en tono y articulación. Posteriormente, los elementos elegidos son marcados mediante herramientas de visualización o algoritmos de segmentación. Finalmente se recolectan en una base de datos.
A groso modo, la manera en cómo se lleva a cabo la síntesis es la siguiente:
Normalmente los fonemas elegidos difícilmente reúnen de manera natural los requerimientos para darle a la frase producida la suficiente inteligibilidad por lo que hay que realizar dos tareas adicionales. La primera tarea consiste en hacer modificaciones en la prosodia. La segunda tarea tiene que ver con la “suavización” de las transiciones de los difonemas ya que son muy notorias debido a las ya mencionadas variaciones de amplitud y frecuencia.
Algunos ejemplos de síntesis por difonemas se encuentran en los audios a continuación:
Todas las voces son originales de FESTIVAL y se pueden encontrar detalles del sistema en su sitio oficial. La primera frase es inglés americano, la segunda inglés británico y la cuarta español europeo.
Bilbliografía
Birkholz, P., & Jackel, D. (2003). A three-dimensional model of the vocal tract for speech synthesis. Of the 15th International Congress of …. Retrieved from http://rickvanderzwet.nl/trac/personal/export/360/liacs/API2010/workshop1/birkholz-2003-icphs.pdf
Birkholz, P., Jackèl, D., & Kroger, B. (2006). Construction and control of a three-dimensional vocal tract model. Acoustics, Speech and Signal. Retrieved from http://ieeexplore.ieee.org/abstract/document/1660160/
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Fant, G. (n.d.). Acoustic theory of speech production : with calculations based on X-ray studies of Russian articulations. Retrieved from https://books.google.com.mx/books/about/Acoustic_Theory_of_Speech_Production.html?id=qa-AUPdWg6sC&redir_esc=y
Homer Dudley’s Speech Synthesisers. (n.d.). Retrieved from http://users.polytech.unice.fr/~strombon/SSI/z.Supplements/vocoder/http___www.obsolete.pdf
Klatt, D. H. (n.d.). Software for a cascade/parallel formant synthesizer. Retrieved from http://www.fon.hum.uva.nl/david/ba_shs/2009/klatt-1980.pdf
Stevens, K., Kasowski, S., & Fant, C. (1953). An electrical analog of the vocal tract. The Journal of the Acoustical. Retrieved from http://asa.scitation.org/doi/abs/10.1121/1.1907169
Line Spectral Pair (Itakura, 1979) es un método de parametrización, o cuantización de una señal de voz que parte del ya mencionado Linear Predictive Coding. Se genera a partir de la ecuación (1) del filtro A(z) que representa el tracto vocal.
![]()
Se plantea que en el polinomio de los coeficientes del filtro se agregan un par de elementos P(z) y Q(z) que representan la glotis en el momento de abrirse y de cerrarse respectivamente. De ahí que uno lleve signo positivo y otro negativo, se representa como (2) y (3)

Donde P(z) y Q(z) se relacionan con (1) de la siguiente forma:
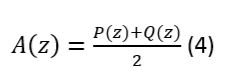
En la práctica, la glotis nunca está totalmente cerrada ni totalmente abierta (McLoughlin, 2009). Esto significa que los polinomios añadidos son al final de cuentas más elementos para cuantizar nuestra señal de voz, consiguiendo darle más naturalidad que cuando se limita a la representación con coeficientes LPC.
Otra ventaja que tiene este sistema de parametrización es que las raíces del polinomio (2) corresponden específicamente a las frecuencias formantes de la señal de voz parametrizada. A partir de ahí podemos llevar a cabo reconocimiento y/o síntesis de voz. A éste conjunto de frecuencias obtenidas se le conoce como Line Spectral Frequencies o LSF.
La figura 1. Muestra gráficamente la comparación entre LPC y LSP. La gráfica azul está formada a partir de los valores en LPC y los puntos rojos y verdes corresponden a P(z) y Q(z) respectivamente. Podemos apreciar una mayor cantidad de puntos cuando se incluyen los polinomios, esto en la práctica nos da una representación de señal de voz mucho más completa que al utilizar LPC.
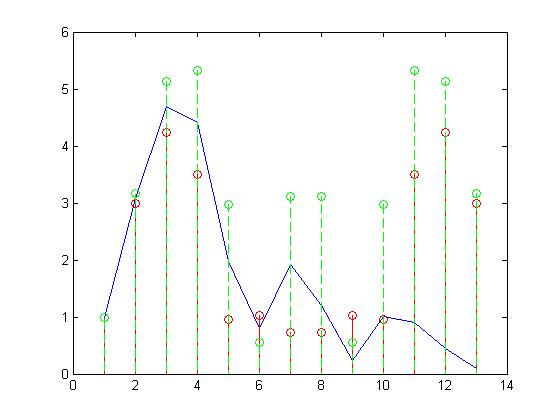
Figura 1. Representación gráfica de LSP contra LPC
El audio a continuación nos permite escuchar una señal de voz orignal y su versión sintetizada utilizando LSP como parametrización.
Referencias
Itakura, F. (1975). Line spectrum representation of linear predictor coefficients of speech signals. The Journal of the Acoustical Society of America, 57(S1), S35-S35.
McLoughlin, I. V. (2008). Line spectral pairs. Signal processing, 88(3), 448-467.
El título se traduce como Síntesis de Voz de Español del centro de México usando Modelos Ocultos de Markov. Fue un trabajo que se presentó en el 13th Annual International Conference on Information Technology & Computer Science organizado por Atiner. Llevado a cabo el día 15 al 19 de mayo de 2016.
El artículo revisa una parte del trabajo de tesis doctoral en el que se está trabajando. Relata como se llevó a cabo en la facultad, la adaptación a español mexicano del sistema de síntesis de voz HTS, propuesto originalmente por el Dr Tokuda y su equipo.
Fue producto de dos meses de trabajo, afortunadamente, tuvo buena recepción en el congreso. Se comparte autoría con el Dr Abel Herrera y con el MI Fernando Del Río, del Laboratorio de Tecnologías del Lenguaje de la Facultad de Ingeniería de la UNAM.
El Abstract del artículo es el siguiente:
The current century has proved being relevant in the design of new speech synthesizers. The incorporation of Hidden Markov Models HMM has changed the paradigm in the design of concatenative speech synthesizers. Such systems are called HMM text to speech synthesis (HTS). This paper describes a version adapted to central Mexico Spanish. A MOS test shows an intelligibility score of 3.4 and 3.1 of naturalness
Adjuntamos el artículo a ésta sección del blog como hemos venido haciendo con trabajos académicos anteriores. Descargar el texto en el vínculo abajo:
