Desde principios del siglo XX se han realizado distintos esfuerzos para generar “máquinas parlantes”, o de manera más correcta: Realizar Síntesis de Voz. Sin embargo, a casi un siglo de que apareció el primer sintetizador de voz eléctrico de Homer Dudley que se tiene documentado (“Homer Dudley’s Speech Synthesisers,” n.d.) llamado VODER (ver figura). No se ha terminado de lograr el sueño de tener un sistema de síntesis de voz que resulte indistinguible de la voz humana. Si bien las voces sintéticas de la actualidad cumplen casi cabalmente el requisito de inteligibilidad, aún no es así con el de la expresión. La combinación de estos dos es lo que dota de naturalidad a los sistemas de voz artificial.

Existen tres sistemas de síntesis vocal: síntesis de formantes, síntesis articulatoria y síntesis concatenativa. A continuación, se explica con detalle en que consiste cada uno.
- Síntesis de Formantes
Se define como frecuencias formantes a aquellas frecuencias características de un fonema. Tales sonidos permanecen constantes en cada emisión de frase, independientemente de la entonación o intensidad con la que la frase haya sido producida. Gracias a ésta característica sabemos que los fonemas pueden ser identificados en todo momento por estas frecuencias.
Fisiológicamente hablando, las formantes son resultado de las resonancias producidas a lo largo del tracto vocal de la onda sonora proveniente de la glotis que tuvo su origen en la vibración de las cuerdas vocales producida por una corriente de aire en los pulmones.
En la voz humana existen dos tipos de sonidos: vocales y sordos o no-vocales, los primeros son resultado de la vibración de las cuerdas vocales y los segundos resultan del flujo de aire que pasa directamente de los pulmones al tracto vocal.
Este proceso de generación artificial de formantes se puede lograr en un sistema de procesamiento de señales electrónicas. La señal proveniente de las cuerdas vocales se simula con una fuente sinusoidal. Los sonidos no-vocales, por su parte, se emulan a través de una fuente de ruido blanco. Las frecuencias formantes se logran pasando dicha fuente a través de un conjunto de filtros pasa banda. Un modelo que ha sido referente en este tipo de sistemas de fuente-filtros es el sintetizador de Klatt (Klatt, 1982) el cual fue de los primeros sistemas de síntesis en software cuyo algoritmo y código fuente se publicaron a detalle.
- Síntesis Articulatoria
La síntesis articulatoria está basada principalmente en el trabajo de Fant (Fant, 1970) que comenzó desde principios de los 60. Este tipo de síntesis pretende modelar las características físicas haciendo un estudio de la geometría del tracto vocal, principalmente de su largo y su área transversal. Posteriormente mediante ecuaciones de movimiento de fluidos se hace un modelo matemático de los fenómenos acústicos que tienen lugar adentro del tracto.
El concepto físico de la presión que el aire ejerce sobre el tracto vocal, así como el chorro de aire que viaja dentro de él se simplifica observando el tracto vocal como una serie de tubos interconectados. Así como el tejido del tracto vocal cambia su grosor de acuerdo con el sonido que se emite, cada uno de estos tubos tiene un diámetro distinto correspondiente a un fonema determinado.
Este modelo tubular es referente en dos tipos de síntesis: la de circuitos acústicos y la de Linear Predictive Coding o LPC. Se hablará de LPC y cómo utiliza el modelo tubular más adelante en este documento, en lo referente a circuitos acústicos podemos mencionar que el modelo tracto vocal-tubular fue muy popular a mediados del siglo veinte ya que constituyó el principio para la elaboración de una familia de sintetizadores de voz eléctricos.
Muchos de ellos fueron llevados a la práctica utilizando analogías acústicas-eléctricas. Destaca el trabajo de Stevens, Kasowski con Fant (Stevens, Kasowski, & Fant, 1953). La síntesis articulatoria perdió un poco de popularidad durante los 60 y 70, no fue sino hasta 1982 con el trabajo de Maeda que se reutilizó la analogía electro-acústica y sin duda al día de hoy el trabajo más relevante donde se emplea síntesis articulatoria es Vocal Tract Lab (Birkholz & Jackel, 2003; Birkholz, Jackèl, & Kroger, 2006), el cual continúa vigente en su interesante proyecto en el sitio vocaltractlab.
- Síntesis Concatenativa
Sin importar cómo fueron generados los fonemas, ya fuera grabadas por una persona o mediante una parametrización de la que se hablará más adelante. Para hacer síntesis es necesario es necesario enlazar los fonemas uno con otro luego de ser producidos. A este tipo de síntesis de voz se le conoce como síntesis concatenativa.
La síntesis concatenativa es la más eficiente en sistemas de síntesis al día de hoy. En la síntesis concatenativa se pueden modificar más detalladamente las unidades mínimas de lenguaje logrando una mayor naturalidad cuando éstos se producen.
Como consecuencia de lo anterior, la inteligibilidad y entonación de una voz artificial de síntesis concatenativa superan a aquellas logradas con síntesis articulatoria o con síntesis de formantes.
Los métodos para emular la prosodia (tono y duración) en la concatenación de las palabras son principalmente los basados en el principio de Suma-Traslape (Overlap-Add), en estos métodos destacan PSOLA, MBROLA y selección de unidades.
Se dice que (Dutoit, 2008) para producir lenguaje hablado de manera inteligible, se requiere de la habilidad de generar lenguaje continuo coarticulado. Lo cual nos conduce a pensar que los puntos de transición entre fonemas son mucho más importantes para la inteligibilidad de lo que son los segmentos estables. Incluso los fonemas vocales largos y sostenidos varían en amplitud y frecuencia, además de que contienen elementos inarmónicos.
Con base en éste argumento, la síntesis de voz concatenativa busca inteligibilidad “pegando” trozos de habla en lugar de fonemas aislados. Esto conlleva a una mejor coarticulación.
- Síntesis Concatenativa basada en Difonemas
Un primer intento de lograr una concatenación más precisa es mediante el uso de difonemas como unidades mínimas para producir lenguaje hablado.
Normalmente, el difonema comienza y termina con una parte estable como se muestra en la figura

El problema es que la cantidad de difonemas presentes en un idioma es enorme. Típicamente una base de datos de difonemas es de al menos 1500 unidades. En términos prácticos, tres minutos de habla muestreados a 16 KHz con resolución de 16 bit suman alrededor de 5 MB.
Para resolver este problema, se busca una lista de palabras donde aparezca al menos dos veces cada difonema. El texto se lee por un locutor profesional para evitar mucha variación en tono y articulación. Posteriormente, los elementos elegidos son marcados mediante herramientas de visualización o algoritmos de segmentación. Finalmente se recolectan en una base de datos.
A groso modo, la manera en cómo se lleva a cabo la síntesis es la siguiente:
- El sintetizador recibe la entrada fonética y se realiza un procesamiento previo de lenguaje (se hablará más delante de dicho proceso).
- Se establece duración, tono y tipo de fonema.
- Se recolecta de la base de datos una serie de fonemas candidatos para llevar a cabo la síntesis.
Normalmente los fonemas elegidos difícilmente reúnen de manera natural los requerimientos para darle a la frase producida la suficiente inteligibilidad por lo que hay que realizar dos tareas adicionales. La primera tarea consiste en hacer modificaciones en la prosodia. La segunda tarea tiene que ver con la “suavización” de las transiciones de los difonemas ya que son muy notorias debido a las ya mencionadas variaciones de amplitud y frecuencia.
Algunos ejemplos de síntesis por difonemas se encuentran en los audios a continuación:
Todas las voces son originales de FESTIVAL y se pueden encontrar detalles del sistema en su sitio oficial. La primera frase es inglés americano, la segunda inglés británico y la cuarta español europeo.
Bilbliografía
Birkholz, P., & Jackel, D. (2003). A three-dimensional model of the vocal tract for speech synthesis. Of the 15th International Congress of …. Retrieved from http://rickvanderzwet.nl/trac/personal/export/360/liacs/API2010/workshop1/birkholz-2003-icphs.pdf
Birkholz, P., Jackèl, D., & Kroger, B. (2006). Construction and control of a three-dimensional vocal tract model. Acoustics, Speech and Signal. Retrieved from http://ieeexplore.ieee.org/abstract/document/1660160/
Dutoit, T. (2008). Corpus-Based Speech Synthesis. In Springer Handbook of Speech Processing (pp. 437–456). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_21
Fant, G. (n.d.). Acoustic theory of speech production : with calculations based on X-ray studies of Russian articulations. Retrieved from https://books.google.com.mx/books/about/Acoustic_Theory_of_Speech_Production.html?id=qa-AUPdWg6sC&redir_esc=y
Homer Dudley’s Speech Synthesisers. (n.d.). Retrieved from http://users.polytech.unice.fr/~strombon/SSI/z.Supplements/vocoder/http___www.obsolete.pdf
Klatt, D. H. (n.d.). Software for a cascade/parallel formant synthesizer. Retrieved from http://www.fon.hum.uva.nl/david/ba_shs/2009/klatt-1980.pdf
Stevens, K., Kasowski, S., & Fant, C. (1953). An electrical analog of the vocal tract. The Journal of the Acoustical. Retrieved from http://asa.scitation.org/doi/abs/10.1121/1.1907169

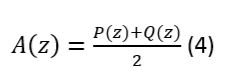

 (2)
(2)