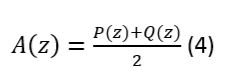Antes de hablar de la mezcla de audio, vale la pena presentar la descripción de un sistema de grabación de sonido:

La figura muestra el diagrama a bloques de un sistema de grabación de sonido. Como cualquier sistema físico está compuesto de entradas y salidas. En un esquema de audio sólo existen dos tipos de entrada: micrófono o línea. Tanto uno como el otro entran a un bloque de mezcla antes de pasar al sistema de grabación.
La mezcladora de audio como su nombre lo dice, permite mezclar dos o más señales de manera simultánea, permitiendo múltiples entradas a una sola salida. En términos musicales podemos tener varios instrumentos o voces sonando al mismo tiempo.
Pero además de actuar como un sumador de señales de audio el mezclador también permite regular la presencia que cada señal tendrá a la salida, para evitar por ejemplo que un instrumento de acompañamiento impida que se escuche con claridad la voz del cantante. La mezcladora tiene también un ecualizador con el cual podemos modificar las características acústicas de cada señal de audio que entra a la mezcladora. Como se vio en la primera sesión, los sonidos graves corresponden a bajas frecuencias y los agudos tienen equivalente en las frecuencias altas.
Hay varios tipos de mezcladores de audio pero todos tienen en común los siguientes controles: Ganancia de amplificación, ecualización y auxiliares.
Veamos cada uno a detalle.
Ganancia:
Este control nos permite modificar el grado de amplificación que se desea en la señal de entrada, en términos matemáticos la ganancia se define de la siguiente forma:
Señal de salida= Ganancia*Señal de entrada
La ecuación nos permite ver que la ganancia no es más que un factor multiplicador que incrementa la señal de entrada, por ejemplo, si la señal de entrada es igual a 20 dB, y la ganancia está sintonizada a 4, la señal de salida tendrá un valor de 80 dB.
Para utilizar un leguaje más musical podemos deducir que la ganancia nos permite controlar el volumen de la señal y nos permite generar sonidos más fuertes o más débiles. Por lo general el control de ganancia está marcado por el término en inglés GAIN.
Ecualización:
El siguiente elemento en común que encontramos en una mezcladora de audio es la sección de ecualización. La ecualización de audio nos permite interactuar con las frecuencias de una señal con objeto de realzar o atenuar determinados elementos.
Para apoyar esta sección, voy a valerme de un texto de J.J.G. Roy encontrado en la página http://www.sonidoyaudio.com.
Roy divide su sección hablando de diferentes márgenes de frecuencia: graves, medios y agudos y hace hincapié en que las frecuencias más problemáticas son aquellas entre los 300 Hz y 10 kHz, en donde el recomienda atenuar más que amplificar. Se habla de problemático dado que es en ese rango donde la mayor parte de los instrumentos musicales –incluida la voz humana- tienen presencia, por lo cual es muy difícil modificar un elemento sin alterar los demás.
GRAVES
20-50 Hz
Las frecuencias que la componen se sienten más que se escuchan. Corresponden a esa sensación que nos produce un automóvil con grandes bocinas para graves o los sonidos graves en un antro o baile: el sonido no es muy perceptible pero pueden moverse hasta los muebles.
“Es una banda que añade un matiz bastante orgánico a la mezcla, pero hay que tratarla con precaución porque si la amplificamos demasiado, nos encontraremos con una importante reducción del margen dinámico y, por tanto, una disminución del volumen final de la mezcla y, sobre todo menor definición de la misma”. Señala Roy en sonidoyaudio.com. Debemos tomar en cuenta que son pocos los equipos de audio domésticos que tienen capacidad de reproducir este rango de frecuencias por lo que no vale la pena hacer muchos ajustes a esta banda.
63-80 Hz
Si el bajo y el bombo han quedado algo apagados, esta es la banda que hay que modificar para conseguir esa pegada que andamos buscando. También añade calidez a la mezcla sin reducir la definición de las voces, guitarras o metales solistas.
Es importante no amplificar demasiado esta banda de lo contrario tendremos un sonido grave semejante a un bufido que hará vibrar demasiado los objetos cercanos a nuestras bocinas.
100-160 Hz
Si empleamos percusiones de mano (congas, instrumentos étnicos, etc), cuyo sonido tiene un fuerte componente resonante, el cual puede llegar a saturar la mezcla de bajos, esta es la frecuencia apropiada para recortar.
Esta banda es la que proporciona una buena calidad de graves en una zona destinada a ser reproducida en altavoces domésticos. Hay que tener cuidado con ella por los mismos motivos citados anteriormente, a los que hay que sumar la ecualización de las demás bandas de bajos.
200-250 Hz
Estas frecuencias suelen ser las culpables de un sonido demasiado cargado de graves en las guitarras acústicas. Un poco de ganancia en esta región puede añadir cuerpo a una mezcla demasiado fina, pero también se puede hacer que el bajo suene poco claro.
Para definir el bajo es más interesante recortar esta banda que aumentar los medios o agudos. La mezcla será más clara y cálida que si optamos por aumentar los agudos.
MEDIOS
315-400 Hz
Si la mezcla global parece velada y sin detalles, ésta es la banda que debe ser recortada; tanto con las pistas individuales como las vocales. Para mejorar la inteligibilidad de la mezcla, manteniendo la calidez, empezaremos a trabajar en esta banda, antes que aumentar los medios o agudos.
500-800 Hz
Un volumen demasiado alto de esta banda conferirá al sonido un aspecto duro o rígido; esto es, si el mazo del bombo parece estar golpeando una caja de cartón, o parece que la reverberación está demasiado realimentada. Esta banda suele disminuirse razonablemente para que la mezcla no pierda cuerpo pero sin que resulte desagradable.
1-2 kHz
Para mejorar la inteligibilidad sin añadir sibilancia se suele aumentar la ganancia de esta banda, porque suele devolver la claridad y frecuencia fundamental de las guitarras con demasiada distorsión.
Por otro lado, un aumento exagerado de esta banda puede hacer que el sonido de la mezcla se parezca más a un atasco de tráfico con todos los automóviles abusando del claxon.
AGUDOS
2,5 – 4 kHz
Esta es la zona en la que el oído humano es más sensible. Esto supone que, cualquier pista que necesite ser destacada de las demás, se beneficiará de un aumento de estas frecuencias, pero un aumento exagerado provocará una importante fatiga acústica. Si la mezcla suena demasiado agresiva o dura, tal vez esta banda esté demasiado alimentada en varias pistas.
Un error cometido frecuentemente sucede cuando de aumentan los agudos de la mezcla para compensar la propia fatiga acústica durante el trabajo. De este modo, cuando los oídos han descansado, pongamos pasadas unas horas, en la siguiente sesión de mezcla, ésta suena demasiado brillante y agresiva.
Normalmente se suele recortar esta banda y trabajar sobre otras.
5 – 10 kHz
En esta banda reside la mayor parte de la sibilancia vocal, aunque la de una voz femenina puede llegar hasta los 11 o 12 kHz. Pero, aunque rebajar la ganancia en estas bandas mejora los problemas de siseo, también reduce la articulación, expresividad, y respiración de la voz. Es por esto que, para evitar que el remedio sea peor que la enfermedad, se utilicen aparatos llamados de-esser.
Un aumento en la zona superior de esta banda supone destacar la vibración de la caja de la batería, el golpe de la baqueta sobre los aros y el chasquido de la maza en el bombo. Lógicamente, una ganancia exagerada provocará un exceso de siseo y agresividad.
Para completar la parte de ecualización adjunto una tabla con los equivalentes en frecuencia de los instrumentos más comunes.

Paneo:
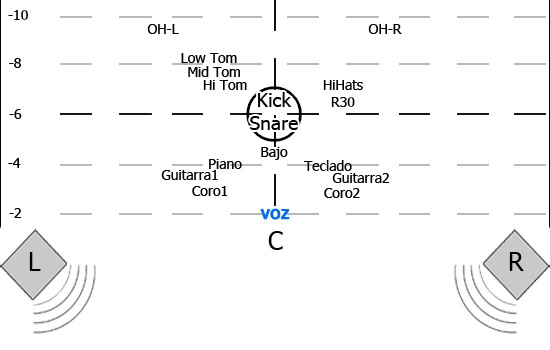
Este control tiene una función simple: Distribuir el sonido del lado derecho o izquierdo de nuestro sistema estereofónico. Es importante utilizar el paneo para lograr una mayor espacialización del sonido, lo que auditivamente significa tener una aproximación de sonido similar a la que tendríamos de estar tocando los músicos frente a nosotros.
No hay una regla general de cómo distribuir las señales de izquierda a derecha, sin embargo se recomienda siempre en loa música popular hacerlo de la siguiente manera.

Auxiliares:
Esta sección nos permite controlar procesadores de sonido o efectos especiales conectados exteriormente a nuestro mezclador. Generalmente los procesos se controlan desde el dispositivo en sí, el control de auxiliar simplemente manipula la cantidad de efecto que se aplicará en la señal.
Dentro de los efectos más conocidos están el compresor, el ecualizador, el reverb o el distorsionador para guitarra.
Vale la pena hacer mención especial del compresor de audio, y ya que es uno de los procesos más comunes en el audio, he decido dar una entrada especial en el blog a dicho tema.
Fader:
Finalmente hablaremos del control de volumen deslizable conocido también como Fader (significa desvanecedor en inglés).
Este control nos permite manipular la intensidad de cada señal de forma individual, para dejar cada elemento en su debido lugar dentro de la mezcla, la idea de una buena mezcla es que cada parte se distinga perfectamente sin restar importancia la una a la otra. No existe tampoco una fórmula mágica de cómo hacer la mezcla. Todo queda en el gusto del productor, del artista o del ingeniero, sin embargo hay que considerar algunos puntos:
• La línea melódica principal debe ser escuchada en todo momento. En la música popular la línea melódica es por lo general la voz y es importante que se note con la mayor claridad posible.
• La batería y el bajo deben estar presentes dado que la primera lleva el pulso de la canción y el segundo la base armónica y ambas partes forman la estructura musical del tema.
• Los instrumentos de acompañamiento como piano o guitarra deben notarse sin destacar demasiado, su función es la de apoyar a la melodía principal.
• En caso de existir partes solistas de algún instrumento, por ejemplo la guitarra, el ingeniero de mezcla debe estar listo para dar mayor volumen a dicho instrumento en el momento de su solo y posteriormente regresar el volumen a su posición de acompañamiento.