Line Spectral Pair (Itakura, 1979) es un método de parametrización, o cuantización de una señal de voz que parte del ya mencionado Linear Predictive Coding. Se genera a partir de la ecuación (1) del filtro A(z) que representa el tracto vocal.
Se plantea que en el polinomio de los coeficientes del filtro se agregan un par de elementos P(z) y Q(z) que representan la glotis en el momento de abrirse y de cerrarse respectivamente. De ahí que uno lleve signo positivo y otro negativo, se representa como (2) y (3)
Donde P(z) y Q(z) se relacionan con (1) de la siguiente forma:
En la práctica, la glotis nunca está totalmente cerrada ni totalmente abierta (McLoughlin, 2009). Esto significa que los polinomios añadidos son al final de cuentas más elementos para cuantizar nuestra señal de voz, consiguiendo darle más naturalidad que cuando se limita a la representación con coeficientes LPC.
Otra ventaja que tiene este sistema de parametrización es que las raíces del polinomio (2) corresponden específicamente a las frecuencias formantes de la señal de voz parametrizada. A partir de ahí podemos llevar a cabo reconocimiento y/o síntesis de voz. A éste conjunto de frecuencias obtenidas se le conoce como Line Spectral Frequencies o LSF.
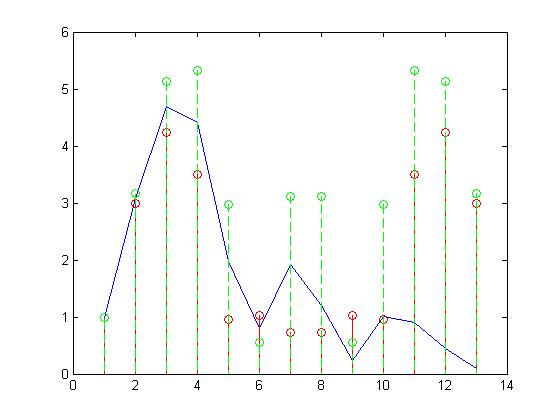
La figura 1. Muestra gráficamente la comparación entre LPC y LSP. La gráfica azul está formada a partir de los valores en LPC y los puntos rojos y verdes corresponden a P(z) y Q(z) respectivamente. Podemos apreciar una mayor cantidad de puntos cuando se incluyen los polinomios, esto en la práctica nos da una representación de señal de voz mucho más completa que al utilizar LPC.
Figura 1. Representación gráfica de LSP contra LPC
El audio a continuación nos permite escuchar una señal de voz orignal y su versión sintetizada utilizando LSP como parametrización.
Referencias
Itakura, F. (1975). Line spectrum representation of linear predictor coefficients of speech signals. The Journal of the Acoustical Society of America, 57(S1), S35-S35.
McLoughlin, I. V. (2008). Line spectral pairs. Signal processing, 88(3), 448-467.
El sistema de Codificación Lineal Predictiva (Linear Predictive Coding) conocido como LPC, (1971) es uno de los diferentes métodos para la producción de voz de manera artificial. Éste sistema parte de una aproximación electrónica al sistema fisiológico en donde la vibración de las cuerdas vocales es una señal sinusoidal que produce los sonidos vocales y una fuente de ruido blanco para los no-vocales. El tracto vocal es modelado mediante un sistema de filtrado cuyas bandas corresponden directamente a las frecuencias formantes del fonema a reproducir. La característica fundamental de LPC es que la señal de voz viene reducida a su expresión más simple. Se conservan solamente las frecuencias formantes del fonema a producir y se deja de lado la vibración que la produjo.
Esto se hace con objeto de ahorrar información, ya que LPC privilegia el contenido del discurso sobre naturalidad del hablante es por eso que la síntesis por LPC tiene esa característica “robótica” en su timbre. Abajo se muestra un ejemplo de una frase codificada usando LPC:
La implementación en software de un sistema LPC está basada en la expresión matemática (1). Donde S(n) representa la señal de voz original, la suma de dicha señal retrasada k muestras pasadas desde 1 hasta p multiplicadas por sus amplitudes Ak es su aproximación artificial. Finalmente e(n) es la diferencia o error existente entre ambas.
(1)
La función de transferencia está representada en la ecuación (2), en donde la expresión (1) puede entenderse como un filtro A(z) cuya entrada es E(z) y su salida S(z).
(2)
La reconstrucción de la señal es obteniendo los valores de los diferentes coeficientes del filtro Ak se hace mediante un sistema de ecuaciones simultáneas que se resuelve por matrices. El método de resolución se conoce como Levinson-Durbin y está ampliamente documentado en la literatura especializada. Generalmente se eligen 13 coeficientes para conservar la inteligibilidad de la frase como fue el caso en el audio arriba mostrado. Éste ejemplo fue implementado en Matlab por Carlos Acosta en el Laboratorio de Tecnologías del Lenguaje de la Facultad de Ingeniería de la UNAM.
El sistema LPC ha sido ya superado por otros sistemas de síntesis de voz que son capaces de reconstruir la señal de voz con mucha mayor naturalidad e inteligibilidad. Se menciona en éste texto dado que es la base teórica de la parametrización de voz del Par Espectral Lineal o Linear Spectral Pair (LSP) el cual sostenemos que es una buena alternativa vigente que puede fácilmente coexistir con los coeficientes de Frecuencia Mel Mel Frequency Cepstral Coefficients (MFCC) que son un estándar en parametrización de voz.
El sistema de filtrado de una señal sinusoidal/ruido blanco sigue en uso y es muy eficiente para la producción de sonidos vocales, independientemente del sistema previo de selección de fonemas que se haya empleado. Este sistema por ejemplo es el recurso de hacer síntesis en el sistema HTS Hidden Markov Models as Text to Speech Synthesis.
Mel Frequency Cepstral Coefficients (MFCC) have been the standard for voice parameterization over the last ten years. Such parameterization scheme works fine in speech recognition given its reduced size and its effectiveness to capture the most essential features of a speech signal.
For synthesis on the other hand, MFCC do not seem to create a convincing voice model on the long term. The author and colleagues investigated such aspect through Mean Opinion Score (MOS) tests, were the listeners had to grade from 0 to 5 phrases produced on the first place by a human speaker followed by a synthesized version of the same phrase using MFCC as speech parameterization (Franco, et. Al. 2016). The results were above the average in both intelligibility and naturalness (3.44 and 3.07 respectively) but it proves that room for improvement exists.
A new study took place (Franco, Herrera 2016). For this study, a different parameterization was included and compared to the previous study where MFCC were used. The chosen parameterization was Linear Spectral Pair (LSP), the theory behind it can be found in a paper by McLoghlin (2008). The authors decided to test it for two main reasons: First, LSP is based on the Linear Predictive Coding (LPC) voice parameterization which models the human vocal tract as a filter. The spectra obtained based on vocal tract models tend to resemble natural speech remarkably. The second reason to use it, comes from its high compatibility with the synthesizer used by the authors which is based on the work of Tokuda and colleagues: Hidden Markov Models as Text to Speech synthesis HTS. That system is pre-programmed with a general parametrization which can be decomposed in both MFCC and LSP (Tokuda, et. al. 1994).
The results from that study averaged 3.4 in naturalness and 3.6 in intelligibility, the numbers are close to those obtained with the MFCC parameterization but the variance found in the grades given by the listeners in the LSP study is much less than the variance found in the MFCC study. This shows that the opinions among the LSP study listeners are much more consistent, therefore the quality of the synthesis is better in general.
Another conducted test was to input the synthesized speech in a Recognition system for forensics application. It was then compared with the original speaker whose voice the system was based on. It showed 0.0072 between original speech and synthesized speech. The closer the distance is to zero, the closer is the synthesis to an ideal case where no difference would appear between artificial and natural speech.
In terms of size LSP speech parameterization files are smaller than MFCC parameterization files this reduction can be important in terms of data transferring and data storing economization.
The authors consider LSP speech parameterization as a new standard in future studies in Laboratorio de Tecnologías del Habla FI UNAM.
References
Franco, C., Herrera Camacho, A. and Del Rio Avila, F. “Conference Proceedings: Speech Synthesis of Central Mexico Spanish using Hidden Markov Models” Athens: ATINER´S Conference paper Series, No: COM2016-2071, 3-12, 2016, Athens Institute for Education and Research
Franco Galván, Carlos Angel. Herrera Camacho, José Abel. Del Río Ávila, Fernando. “Conference Proceedings: Síntesis de Voz en Español hablado en el Centro de México Utilizando MFCC´s y LSP´s” IEEE ROC&C , 2016
McLoughlin, I. V. (2008). Line spectral pairs. Signal processing, 88(3), 448-467.
Tokuda, K., Kobayashi, T., Masuko, T., & Imai, S. (1994, September). Mel-generalized cepstral analysis-a unified approach to speech spectral estimation. In ICSLP (Vol. 94, pp. 18-22).
Una tardía entrada en mi bitácora de actividades musicales. No pasó desapercibida ésta primera etapa del año en cuanto a música, sin embargo no hubo shows en vivo ni grabaciones nuevas.
Fueron dos vídeos, una interpretación de “Oh Darling” a bajo y voz. Con la necedad del epiphone zurdo. Hubo también una composición reciente “Leap Up” dedicada a la persona con quien comienza una nueva aventura. En el caso de ésta última se hizo un ejercicio diferente en el programa de Beatles en el Microscopio.
Se estreno la canción en vivo, tipo Agustin Lara en la XEW.
Se presentó el 28 de noviembre de 2016 en Acapulco Gro. una ponencia resultado de nuestro trabajo de investigación doctoral. Se habló sobre la parametrización utilizada en nuestro sistema de síntesis de voz en español. Causó buena impresión entre quienes asistieron a la charla y se lograron dos posibles colaboraciones entre instituciones. Nuestro abstract es el siguiente:
Los autores han desarrollado un sintetizador basado en HMM’s para el español hablado en el centro de México. En este trabajo, se adecua la parametrización LSP para este sinteizador. Además, se realiza una comparación de dos parametrizaciones de voz: MFCC y LSP. Ambos esquemas están programados como parte del sintetizador antes mencionado. Se realizaron frases de síntesis con cada parametrización y las respectivas pruebas MOS para valorar su calidad. Tanto MFCC como LSP sobrepasan la calificación promedio, pero aún hay espacio para mejora.
El artículo completo se puede descargar aquí: cm-02
Seguimos aquí metiendo información a éste diario de actividades musicales que nos ayuda a mantener la cordura. Empecemos por lo primero:
Martes 13 de Diciembre.
Una comida de fin de año con los profes de la Facultad de Artes de la BUAP significó una nueva tocada con el trío de jazz Illarramendi-Guevara-Franco. Donde dimos rienda suelta al impulso jazzero con estandars como: The Chicken, Night Birds, Take the A Train, Equinox y hasta una versión de Noche de Paz con arreglo de Guevara.
Lunes 19 de Diciembre
El último programa de 2016 de Beatles en el Microcopio. Donde invitamo a Marcelino Cólex igual que hace un año para revivir ese dueto de country-blues llamado “La última Milla”. La verdad es que considerando que decidí ocupar como arma especial una Les Paul en lugar de mi habitual bajo, se logró una sensación agradable haciendo temas de Tommy Flint, el famoso Blue Bossa y hasta una composición Colex/Franco que desde hoy se titula “Alcaline”.
He aquí el link del programa
Finalmente me dí el gusto de participar en una red social de colaboraciones musicales llamada Bandhub es una idea muy atractiva donde un usuario propone un tema con un sólo track, por ejemplo: voz, guitarra. A partir de ahí invita a otros músicos a colaborar con las partes restantes como bajo, batería, coros, etc. Se pueden hacer covers o composiciones originales. En éste caso dimos notas graves a éste hermoso tema Pop de los Beatles llamado “Hold Me Tight”
Noviembre no fue de presentaciones en directo, sin embargo, lo que empezó como un single para compartir en éste mes, terminó en un nuevo LP. Siempre es importante considerar que: Un nuevo álbum, un nuevo aprendizaje
Sin duda es importante buscar que se quede algo nuevo como músicos en cada nueva grabación. En este caso, quiero listar lo que considero fue un reciente aprendizaje :
1. La batería es un instrumento musical muy chingón. Sin embargo y como en toda actividad en la que se empieza a conocer algo nuevo, aún requiero más práctica antes de hacer una línea lo suficientemente profesional. El trabajo quedó digno pero hubo temas como “the last rock and roll” y “sobretodo amor” en donde se nota falta de dominio en los redobles de tarola/caja/snare.
2. Al buscar que el volumen final de un track iguale a los volúmenes de las grandes producciones termina en afectar negativamente el rango dinámico de la pieza musical. Por ésta razón decidí dejar los tracks de forma tal que sus picos máximos quedaran en -3 dB. Este enfoque se utilizó a inicios de los 90 en producciones comerciales como Dangerous de Michael Jackson. Evidentemente los tracks sonarán con menos volumen que un track de gran producción comercial pero se conservará su dinámica y por lo tanto la calidad en los sonidos.
Respecto a éste segundo punto quiero remarcar que lo relevante de los sonidos del track ocurre en el momento de la captura y edición de los mismos. No en la masterización. Queda como aprendizaje el procesar las señales de manera que sean más rica acústicamente en timbre.
Una última actividad que tuvo lugar y para no cerrar el mes en ceros fue la siguiente rendición en guitarra al estándar de jazz Blue Bossa.
Ve sin miedo
Sin duda hay dos elementos clave, por un lado el blues y por otro ese tipo de canciones Rock Pop donde existe un coro de notas largas en la voz sobre un acompañamiento de octavos un poco sobrepasado de agudos. Por ejemplo “Save me” de Remy Zero o “Creep” de Radiohead. La letra desde el principio quería que fuera de aliento: “Ve sin miedo”, no renuncies a ti.
Espíritu Vencedor
La canción que da título al disco, que fue pensada para una mujer muy esforzada en su trabajo.
Aquí tenía ganas de hacer guitarras casi atmosféricas y que la batería y el bajo estuvieran únicamente sugeridos en el fondo. La voz fue pasada por un amplificador de bajo y eso le da esa sensación de estar sonando a través de un radio AM. Sólo en la parte media ocurre una voz con proceso tradicional de micrófono y reverb. Para los más clavados en la teoría les comento que la progresión armónica surgió antes que la melodía y fue generada completamente al azar. Por ésta razón la melodía se adaptó después.
Crear
Ésta canción tiene una letra que describe una situación que, según he visto, es común entre los colegas: “Creer que la música es sólo para conseguir fama y fortuna”. Luego de unos años de ejercer esta hermosa profesión se da uno cuenta de que va mucho más allá de todo eso.
Musicalmente quería una influencia tipo Creedence, con guitarras acústicas en cada lado de la estereofonía, llevando la armonía de manera casi percusiva. Hay también un piano de fondo y un bajo casi hermanado con el bombo.
D es de Dinosaurio
Es una composición de Alonso Arreola que aparece en su álbum “Música para ser niño”. El tema siempre me gustó mucho y lo trabajé con el músico poblano Gil Gallardo para que me obsequiara ese lindo sonido de Sax soprano.
The Last Rock and Roll
Este tema empezó como una improvisación de batería en 4/4 pensando en términos rocanrroleros. De ahí la melodía surgió una vez terminado el ritmo, de entrada se ideó la frase This is the last rock and Roll, se sabía que la letra tenía que llevar temática tipo “Closing Time” de Semisonic.
La guitarra principal tiene un riff que seguramente tuvo que ver con “I Saw her Standing There”, la guitarra segunda hace ritmo a contratiempo. Con un rasgueo de sonido muy Stratocaster.
El bajo por su parte surgió de una clase de bajo con Alonso Arreola, en donde me sugería seguir con el bajo diferentes elementos de la batería en una misma frase musical. Es por eso que el bajo empieza con un aire muy desenfadado siguiendo al bombo, en el verso sin embargo empieza a ir a tiempo con la tarola y hace el remate haciendo octavos con los contratiempos. La voz la imaginé como ciertos temas de Lennon, mucho reverb y delay, la interpretación también tiene cierta influencia suya. La letra hace referencia a aquellos días con Eslabón cuando tocando en algún bar de Puebla me daba cuenta de que no estaba ya contento en ese entorno.
Lazo Cerrado
Usamos el término en ingeniería para denotar a un sistema cuya salida se retroalimenta a la entrada, como una caja de WC por ejemplo, se vacía y se vuelve a llenar automáticamente. Siempre me gustaron esas palabras y quise usarlas para nombrar éste tema instrumental.
La base percusiva es claramente electrónica, encima de ella va el bajo desarrollando el tema melódico acompañado de una guitarra stratocaster con acordes de séptima mayor que siempre me han parecido relajantes. Aunque el tema B tarta de evocar una momento lúdico para nuevamente caer al tema A. Finalmente aparece un alegre tema C para cerrar la pieza. Esta canción es una suerte de intermedio para seguir la línea de las canciones con letra.
Octafono Markov
Recibe su nombre de dos conceptos, el primero porque está escrita sobre una escala octáfona, es una escala cuyo orden va tono y semitono.
El nombre Markov viene del sintetizador de voz Hidden Markov Models as Text to Speech Synthesis. Es un sistema de cómputo que genera voz artificial en español sobre el que hemos estado trabajando en la UNAM desde hace algunos años.
Las voces que ahí suenan, a excepción de la de un servidor, fueron producto de dicho programa. El resto de los sonidos son bajo, Batería y batería virtual.
Take me Home
La melodía salió mientras caminaba de la tienda a mi casa, no estaba muy seguro de su destino final hasta que a manera de ejercicio decidí pasar a partitura la melodía. Una vez en el papel hubo chance de pensar en una composición a varias voces.
De ahí me acordé de esos himnos religiosos de Palestrina, la letra es una especie de salmo, que si bien no soy religioso, quise ser fiel al género.
Sobretodo Amor
Una canción tanatológica según me dijeron. El mensaje del tema es que, independientemente de cómo quieras morir, de poco vale una vida sin amor por otros y de otros a uno. Disfruté mucho el solo de guitarra, sin duda me ayudó a sacar mi lado blusero en la guitarra. Oculto hace tiempo.
Love for Granted
Este tema tiene mucha influencia de Badfinger, Fleetwood Mac o Wings. Melodía muy accesible con un coro fácil de seguir. Imaginé una lírica más desde un punto de vista femenino que masculino, en un mundo ideal ésta rola la imagino cantada por Suzy Quatro o Sheryl Crow de ahí que fuera en inglés.
La base rítmica es simple, batería marcando los tiempos y bajo haciendo octavos rítmicamente mientras melódicamente soporta la armonía de la canción. Las guitarras van contestando a la voz con frases melódicas a veces y marcando el acorde otras tantas.
Siempre hay lugar para una canción pop, éste fue el postre del disco.
Esto es a groso modo “Espíritu Vencedor”, el segundo álbum de un servidor en donde está a cargo de todo. Es desgastante trabajar así y hasta cierto punto me pierdo de las contribuciones de otros músicos, sin duda la siguiente entrega será con una banda completa. Por otro lado debo decir que me divirtió mucho tocar instrumentos como guitarras o batería que normalmente no toco, en ese sentido fue muy ilustrativo.
El mes sólo tuvo una presentación que fue el día 4. En un homenaje a los rockeros poblanos de antaño. Eslabón participó invitado por Raúl Núñez, tocando cuatro rolas de rock and roll de los 60 en las versiones cómo se conocieron en México. Popotitos por ejemplo, grabada por Enrique Guzmán (con los Teen Tops) es una adaptación del tema Bonnie Moroni, que al día de hoy indentifico más por John Lennon que por sus intérpretes originales.
Nunca he sido entusiasta del rock de los 60 en sus versiones al español, sin embargo fue bueno el pretexto para agarrar mi Epiphone Viola y juntarme a hacer ruido con Víctor Illarramendi y Marco Quintana. Se sumó al palomazo mi amigo el saxofonista Orlando Flores y por supuesto que estaba Ramón Durañona, en ésta ocasión haciendo la función de ingeniero de sonido. Considerando el PA con el que tocamos fue como hacer cirugía con cuchillos de cocina, triste situación. En la guitarra solista fue de invitado Rogelio Rodríguez, un experimentado requinto de trio romántico que se animó a tocar guitarra eléctrica en esta ocasión. Aparece a la izquierda de Marco en la foto, una sentida disculpa pero no recuerdo los nombres de los otros señores.
El secreto de mantener musical éste mes fue jugando al ermitaño en el estudio de grabación. Lo que iba a ser simplemente un single en el mes de noviembre se amplió con algunos temas más a un álbum completo con temas diversos entre sí. Ya lo compartiré en su debido momento, mientras tanto dejamos aquí uno de los temas que ya había grabado en julio pero no había llevado al YouTube.
De Alonso Arreola: D es de Dinosaurio. Presentando a Gil Gallardo en el saxo:
Este clásico de Paul McCartney inició como un ejercicio de técnica. El objetivo fue hacer un arreglo para bajo solo y terminó convirtiéndose en un single más. Pocas piezas instrumentales figuran en la discografía así que siempre habrá espacio para una más.

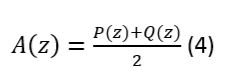

 (2)
(2)



