Se ha visto que modificar duración y tono en una señal de voz (prosodia) no son operaciones triviales. De manera intuitiva, el lector podría pensar que, modificaciones a tono y duración se consiguen interpolando muestras y re-muestreando la señal. Los resultados de realizar tal proceso equivalen a aquellos observados cuando se modifica la velocidad de reproducción de una cinta de audio analógica, es decir: el tono sube o baja de manera exagerada. Se han buscado alternativas para resolver éste problema, uno de los más eficientes ha sido el procesamiento de la señal mediante un algoritmo conocido como TD-PSOLA (Stylianou, 2008).
Time Domain Pitch Synchronous Overlap Add (Fragmentación y traslape de la señal sincronizada en tono en dominio del tiempo). Tal cual su nombre lo indica, el algoritmo tiene la siguiente estructura:
- Se analizan los distintos periodos en la señal de voz y se colocan indicadores (pitch marks)
- Hacer un ventaneo (fragmentación de la señal) con una cierta duración.
- Identificación de la frecuencia fundamental F0 en cada uno de los segmentos contenidos en las ventanas.
- Si se desea aumentar la duración, se repiten ciertos segmentos para aumentar el periodo. Si por el contrario la intención es volverla más corta, se eliminan algunos segmentos.
- Si se desea cambiar el tono se reacomodan las ventanas con modificaciones de la duración entre una y otra, dependiendo si se quiere aumentar o disminuir la frecuencia.
- Finalmente se suman las ventanas resultantes para realizar la síntesis
En el enlace abajo se muestran ejemplos de síntesis usando TD-PSOLA, la primera y segunda frase muestran sonido sintetizado a partir de texto. La diferencia entre ambas es la entonación que fue modificada de forma artificial. El tercer audio muestra una señal de voz grabada sin modificaciones y la cuarta es ésta misma señal con modificaciones en tono y duración.
A continuación, presentamos los detalles del algoritmo arriba mencionado:
Se tiene una señal de voz como se ve en la figura 1.
 Figura 1 “Señal de voz”
Figura 1 “Señal de voz”
En esta señal es necesario hacer una detección de las partes periódicas de la misma, para ello hay varios métodos. Aquí describimos el procedimiento propuesto por Goncharoff (Goncharoff & Gries, 1998). En primer lugar, se buscan secuencias numéricas que se incrementen y decrementen con cierta regularidad. Una vez hallados estos periodos se identifican mediante marcas de tono o pitch marks. Posteriormente se separa la señal en tramas o frames, cada frame tiene una duración de dos periodos. La ventaja de tener éstas ventanas como unidades aisladas es que podemos combinarlas teniendo sus puntos centrales en la frecuencia principal. Luego se traslapan unas con otras y se tiene una reconstrucción de la señal original. La figura 2 muestra un diagrama de la misma.

Figura 2 “(1) Detección de pitch marks. (2) Aplicación de ventanas Hanning. (3) Separación en frames. (4) Reconstrucción de la señal original.
Se recomienda la ventana de dos periodos para facilitar la reconstrucción de la onda en el momento del traslape, así como se ilustra en la figura 3.

Figura 3 “Traslape de segmentos”
2. Modificaciones de tono y duración.
Precisamente la ventaja de hacer ésta separación de la señal en tramas es lo que nos permite hacer modificaciones en duración y tono. Para modificar la duración es necesario duplicar algunas de las tramas. Por su parte si se busca un acortamiento de la duración de la señal, algunas de las tramas deben ser eliminadas. La figura 4 ilustra éste concepto.
La modificación del tono se logra mediante la recombinación de las tramas. En éste caso es necesario modificar la duración de las pitch marks. Vale la pena mencionar un ejemplo para ilustrar éste concepto:
- Se tiene un segmento de voz con un tono de 100 Hz (10 ms entre cada pitch mark)
- Se realiza el ventaneo de Hanning
- Sí se colocan las ventanas a una distancia de 9 ms y luego se hace la suma-traslape, se obtendrá ahora un tono de 111 Hz.

Figura 4 “Traslape para modificar tono”
Para el caso de la modificación del tono, es necesario alterar la duración de los periodos entre las pitch marks. La consecuencia de esto puede ser la obtención de una señal más corta en el tiempo. Por ésta razón, a veces es necesario duplicar algunos frames en afán de preservar la duración original de la señal.
Detallaremos ésta explicación con un ejemplo:
- Se tiene un tono de 100Hz ventaneado con 5 frames cada uno con una separación de 10 ms. Es decir, hay una duración total de (5-1) *10 ms= 40ms entre la primera y la última pitch mark.
- Si deseamos cambiar el tono a 150 Hz es necesario poner la distancia de las pitch marks a 6.6 ms, el probema es que ahora nuestra duración total es de (5-1) *6.6ms= 26 ms.
- Para preservar la duración original, tenemos que duplicar dos frames, de ésta forma volvemos a nuestra duración de 40 ms (7-1) * 6.6 ms =40 ms.
- Detalle de la manipulación de las pitch marks
Como se puede apreciar en las secciones anteriores la base del método TD PSOLA, el elemento crítico son las pitch marks . Se ha dicho que es necesario modificarlas para ejecutar los cambios de duración y tono.
Se mencionó que las pitch marks se hallan mediante un algoritmo de detección. Dichas marcas se pueden representar como una secuencia de análisis Ta= {ta1, ta2,…,taM}, el periodo local entre dos de éstas marcas se define como:
Que no es más que un valor medio entre la pitch mark inicial y la pitch mark final. De éste punto, se hace un ventaneo de la señal para separar en frames, éste se define como:
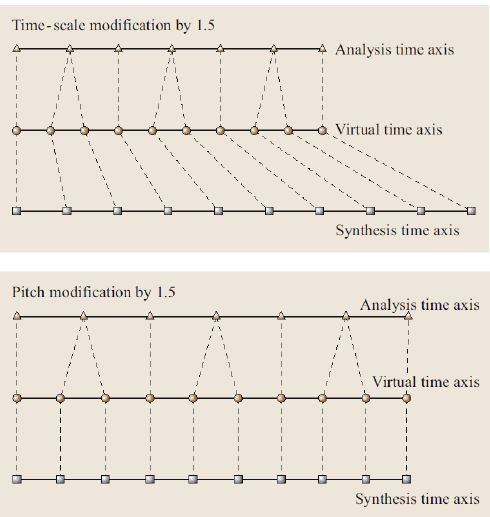
De aquí es necesario crear una secuencia de síntesis de las pitch marks que depende de la duración y cambio en el tono deseados Ts= {tS1, tS2,…,tSM}, la relación de ésta secuencia de síntesis con la de análisis está relacionada por una función M[i] que especifica cuáles frames de análisis deberán corresponder en la síntesis. Ésta función es una suerte de línea de tiempo virtual entre sínteis y análisis, tal como se ve en la figura 5.

Figura 5 “línea de virtual tiempo de pitch marks entre análisis y síntesis”
Multi-Band Resynthesis Overlap Add (MBROLA)
Se habló en párrafos anteriores acerca de dos tareas principales a resolver en la síntesis concatenativa, la primera tiene que ver con la modificación de la prosodia y la segunda con hacer una transición sutil entre fonemas.
El que la transición no sea sutil tiene que ver con una unión incorrecta entre fonemas, la cual puede ser de tres tipos:
Mala unión de Fase (Phase Mismatch): Este tipo de problemas ocurren cuando las formas de onda no están centradas en las mismas posiciones relativas dentro del periodo de tiempo en que se encuentran.
Mala unión de Tono (Pitch Mismatch): Sucede cuando ambos segmentos tienen la misma envolvente espectral pero fueron pronunciados con diferentes tonos.
Mala unión de Envolvente de Espectro (Spectral Envelope Mismatch): Esta falla resulta cuando las unidades fonéticas fueron extraídas de contextos diferentes entre sí. La discontinuidad ocurre sólo en un período.
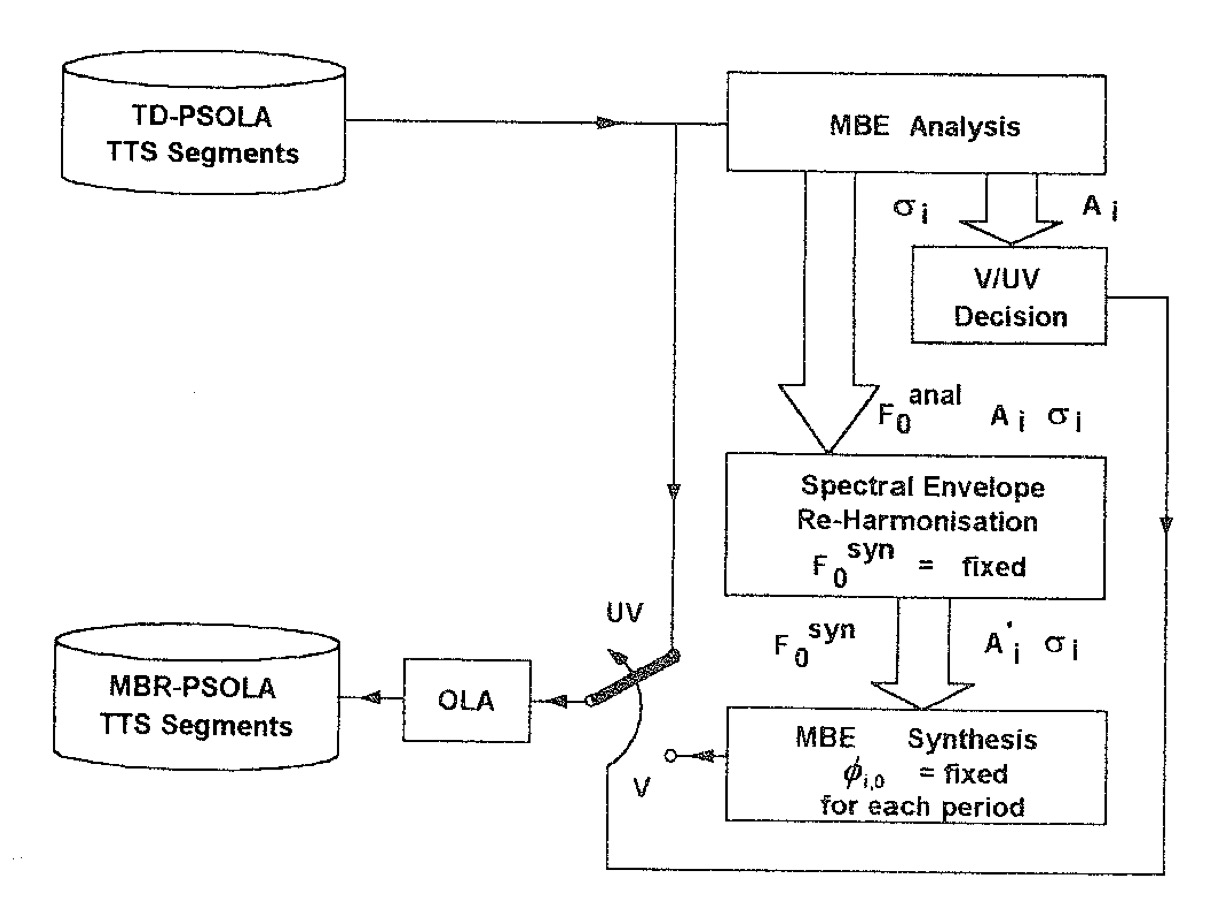
Ante estos problemas de unión, Dutoit y Leich (Dutoit & Leich, 1993)proponen una solución conocida como MBROLA. Este algoritmo deriva directamente del TD-PSOLA, de hecho es muy semejante. La diferencia radica en que no se hace un análisis individual de las ventanas. Ni son necesarias las pitch marks.
Como lo muestra el diagrama, el sistema toma como referencia un difonema procedente de un corpus. El primer paso es diferenciar si es vocal o sordo. Si se trata de un sonido vocal, entonces se separa y se hace un análisis de bandas del mismo. El análisis se lleva a cabo mediante un sintetizador armónico que se encarga de calcular nuevas amplitudes y fases con características regulares. Estos difonemas resintetizados son después concatenados utilizando el método Overlap Add OLA.

Figura 6 “Esquema de MBROLA”
Dado que objetivo de MBROLA es hacer las formas de onda lo más semejantes entre sí. Es esencial el reajuste de fases del que se habló anteriormente y se explicará a continuación con mayor detalle. El ajuste de las ondas se hace en los bordes de la última parte del primer segmento y de la primera parte del segundo segmento. El último borde y el subsiguiente se denotan como SlN y Sr0 respectivamente y los ajustes a los mismos se definen como ML y MR los cuales se obtienen de las siguientes fórmulas:
Para i=0…ML-1 y j=0…MR-1
Para la solución de la mala unión de la envolvente de espectro se usa el algoritmo propuesto por Charpentier y Moulines (Moulines & Charpentier, 1990) el cual consiste en la interpolación de los periodos vocales de tono regular (voiced pitch periods).
Referencias
Dutoit, T., & Leich, H. (1993). MBR-PSOLA: Text-to-speech synthesis based on an MBE re-synthesis of the segments database. Speech Communication. Retrieved from http://www.sciencedirect.com/science/article/pii/016763939390042J
Goncharoff, V., & Gries, P. (1998). An algorithm for accurately marking pitch pulses in speech signals. Proc. of the SIP’98. Retrieved from
Moulines, E., & Charpentier, F. (1990). Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Communication. Retrieved from http://www.sciencedirect.com/science/article/pii/016763939090021Z
Stylianou, Y. (2008). Voice Transformation. In Springer Handbook of Speech Processing (pp. 489–504). Berlin, Heidelberg: Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_24